Markov chain(마르코프 연쇄)
* 20세기 초 수학자 Andrey Markov가 메모리가 없는 확률 과정(stochastic process)인 마르코프 연쇄에 대해 연구함.

* 이 과정에서 state의 개수는 정해져 있으며, state S에서 state S'로 이동하는 과정은 순전히 확률적으로 결정된다. 예를 들어 위 그림의 state 개수는 4개이다. state $S_0$에서 state $S_3$로 옮겨가는 것은 0.1의 확률로 이뤄지고, $S_1$으로는 0.2의 확률로, $S_0$ 자신으로 되돌아오는 것은 0.7의 확률로 이뤄진다. 이 과정은 과거에 대한 정보, 즉 메모리가 존재하지 않기 때문에 순전히 확률적으로 state의 변경이 일어나게 된다. 그리고 이는 다시 말해 상태 전이에 있어서 오직 (s, s') 쌍에만 의지한다는 것과 같은 말이고, 이를 Markov Property라고 한다.
* 위 그림의 예에서 $S_3$은 다른 state로 이동하지 않고 오직 자기 자신의 state로만 1.0의 확률로 남아있게 된다. 때문에 만약 state $S_3$로 이동하게 되면 더 이상의 state 이동은 발생하지 않게 되고, 종료되는데 이를 terminate state라고 한다.
np.random.seed(42)
transition_probabilities = [ # shape=[s, s']
[0.7, 0.2, 0.0, 0.1], # from s0 to s0, s1, s2, s3
[0.0, 0.0, 0.9, 0.1], # from s1 to ...
[0.0, 1.0, 0.0, 0.0], # from s2 to ...
[0.0, 0.0, 0.0, 1.0]] # from s3 to ...
n_max_steps = 50
def print_sequence():
current_state = 0
print("States:", end=" ")
for step in range(n_max_steps):
print(current_state, end=" ")
if current_state == 3:
break
current_state = np.random.choice(range(4), p=transition_probabilities[current_state])
else:
print("...", end="")
print()
for _ in range(10):
print_sequence()
States: 0 0 3
States: 0 1 2 1 2 1 2 1 2 1 3
States: 0 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 3
States: 0 3
States: 0 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 3
States: 0 1 3
States: 0 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 ...
States: 0 0 3
States: 0 0 0 1 2 1 2 1 3
States: 0 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 3* 위 코드에서 볼 수 있다시피, 확률적으로 움직이다가 3에 도달하면 transition이 종료되는 것을 볼 수 있다.
Markov Decision Process(마르코프 결정 과정)
* 1950년 Richard Bellman이 처음으로 논문에 기술한 process이다.

* 마르코프 연쇄와 같이 state는 메모리가 없고 확률에 의해 다른 state로 전이된다. 추가되는 부분은 state의 전이 확률이 정해져있는 것이 아니라 선택에 따라 달라진다는 것이다. 또한 특정 상태 전이는 보상을 포함하고 있다. agent의 목적은 이 보상을 최대화 하는 것이다.
최적의 state value
* bellman은 상태 s의 최적의 state value $V*(s)$를 추정하는 방법을 찾았다. 이 값은 agent가 상태 s에 도달한 후 최적으로 행동한다고 가정했을 때 평균적으로 기대되는 할인된 미래 보상의 합이다.
* bellman은 agent가 최적으로 행동하면 bellman 최적 방정식이 적용된다는 것을 입증했다.

* agent가 최적으로 행동하면, 최적의 현재 state value는 (하나의 최적 행동으로 평균적으로 받게 될 보상) + (이 행동이 유발하는 가능한 모든 다음 상태의 최적 가치의 기대치의 합) 이라는 것을 위 수식을 통해 정리하였다.
* $T(s, a, s')$는 agent가 행동 a를 선택했을 때 상태 s에서 s'로 전이될 확률이다. ex) 그림에서 $T(s_2, a_1, s_0) = 0.8$
* $R(s, a, s')$는 agent가 행동 a를 선택해서 상태 s에서 상태 s'로 이동되었을 때 agent가 받을 수 있는 보상이다. $R(s_2, a_1, s_0) = +40$ 이다.
* $\gamma$는 할인계수이다.
state iteration algorithm
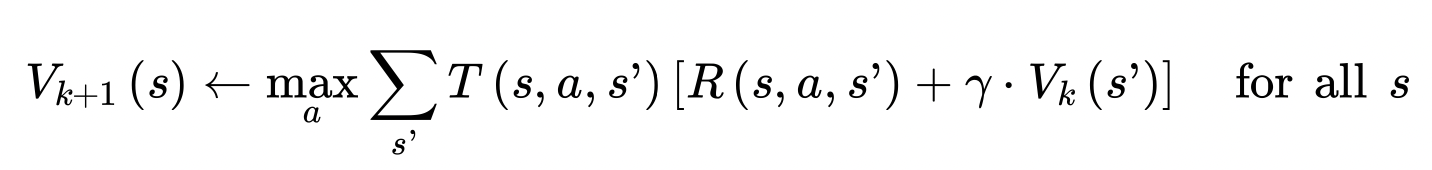
* 알고리즘이 가능한 모든 state에 대해 최적 state value를 추정할 수 있도록 하는 수식이다.
* 모든 상태 가치는 최초에 0으로 초기화 된다. 이후 위 가치 반복 알고리즘에 의해 반복적으로 state를 update하다보면 최적의 state value에 수렴한다.
* 이 식에서 $V_k (s)$ 는 알고리즘의 k번째 반복에서 state s의 추정 가치를 뜻한다.
* 최적의 상태 가치를 아는 것은 특히 policy를 평가할 때 유용하다.
'Deep Learning > Hands On Machine Learning' 카테고리의 다른 글
| Temporal Difference Learning : TD Learning (0) | 2022.01.08 |
|---|---|
| State-Action Value Function(Q Function) (0) | 2022.01.08 |
| PG(Policy Gradient) Algorithm (0) | 2022.01.08 |
| 신용할당 문제(Credit Assignment Problem) (0) | 2022.01.08 |
| 강화학습의 신경망 정책 (0) | 2022.01.08 |


