* 이전까지 포스팅했던 RNN, LSTM 모델들은 모두 단어 vector를 입력으로 받는 모델이었다. 이번 포스팅에서는 단어를 입력으로 받는 것이 아닌 글자 기반 RNN, 글자(Character)를 입력으로 받는 RNN모델에 대해서 살펴보겠다.
1. 글자 단위 RNN 모델(Char RNNLM)
데이터셋 로드
import numpy as np
import urllib.request
from tensorflow.keras.utils import to_categorical
urllib.request.urlretrieve('http://www.gutenberg.org/files/11/11-0.txt', filename='11-0.txt')
f = open('11-0.txt', 'rb') #read binary mode
sentences=[]
for sentence in f: #데이터 한 줄씩 읽기
sentence=sentence.strip() #\n, \r 제거
sentence=sentence.lower()
sentence=sentence.decode('ascii', 'ignore')
if len(sentence)>0:
sentences.append(sentence)
f.close()* 이상한 나라의 앨리스 전문을 다운받아 훈련 데이터로 사용하려고 한다. 데이터는 http://www.gutenberg.org/files/11/11-0.txt 에서 받을 수 있다.
* file을 open해 한 줄씩 데이터를 읽어서 전처리를 한 후 sentences에 append하였다. 주의할 점은 binary data이기 때문에 ascii로 decoding해줘야 한다는 점이다.
데이터셋 join
total_data=' '.join(sentences)
len(total_data)
# 159484* 한 줄씩 sentences에 append했기 때문에 원소들을 모두 join해준다.
단어 집합 생성
characters=sorted(list(set(total_data)))
vocab_size=len(characters)+1
vocab_size
#57* total_data로부터 단어 집합을 생성하였다. 이상한 나라의 앨리스 전문의 길이는 159484이지만, set()함수를 통해 사용된 문자열들의 집합을 추출한 결과 56개의 문자열이 사용된 것을 확인하였다. vocab_size는 집합의 크기 + 1 만큼의 길이를 할당하였다.
훈련 데이터셋 생성
* 앞서 단어 기반의 RNN의 경우 각 문장에서 단어들을 하나씩 늘려가며 훈련용 데이터셋을 생성하였다. 단어 기반의 RNN의 경우 many to one 모델이었던 것을 기억할 것이다. 예를 들면 '나는 코딩을 하였다' 라는 문장을 '나는', '나는 코딩을', '나는 코딩을 하였다' 3개의 문장으로 구분해 데이터셋을 구성한 후 '나는 코딩을'이라는 단어가 모델에 주어지면 '하였다'라는 단어를 예측하는 방식이었다. 때문에 훈련 문장의 가장 마지막 단어를 분리해 y 데이터로 구성하였던 것을 기억할 것이다.
* 글자 기반의 RNN은 단어 기반의 RNN과는 달리 'apple'이라는 단어가 데이터셋에 존재할 때 'appl'이 주어지면 'pple'를 예측하는 many to many 모델이다. 때문에 데이터셋은 'apple'을 x data에 'appl', y data에 'e'를 할당하는 것이 아닌 x data에는 'appl', y data에는 'pple'를 할당하는 방식으로 구성해야 한다. 즉, y data는 x data를 오른쪽으로 한 칸 shift한 것과 같이 구성한다.
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.utils import to_categorical
tokenizer=Tokenizer(char_level=True) #charRNN구성을 위해 char_level=True를 설정
tokenizer.fit_on_texts([characters])
tokenizer.word_index
# {' ': 1,
# '!': 2,
# '"': 3,
# '#': 4,
# '$': 5,
# '%': 6,
# "'": 7,
# '(': 8,
# ')': 9,
# '*': 10,
# ',': 11,
# '-': 12,
# '.': 13,
# '/': 14,
# '0': 15,
# '1': 16,
# '2': 17,
# '3': 18,
# '4': 19,
# '5': 20,
# '6': 21,
# '7': 22,
# '8': 23,
# '9': 24,
# ':': 25,
# ';': 26,
# '?': 27,
# '[': 28,
# ']': 29,
# '_': 30,
# 'a': 31,
# 'b': 32,
# 'c': 33,
# 'd': 34,
# 'e': 35,
# 'f': 36,
# 'g': 37,
# 'h': 38,
# 'i': 39,
# 'j': 40,
# 'k': 41,
# 'l': 42,
# 'm': 43,
# 'n': 44,
# 'o': 45,
# 'p': 46,
# 'q': 47,
# 'r': 48,
# 's': 49,
# 't': 50,
# 'u': 51,
# 'v': 52,
# 'w': 53,
# 'x': 54,
# 'y': 55,
# 'z': 56}* tokenizer에 fit을 해서 단어 집합에 번호를 붙였다.
seq_length=60
n_samples=int(np.floor((len(total_data)-1)/seq_length))
n_samples
train_X=[]
train_y=[]
for i in range(n_samples):
X_sample=total_data[i*seq_length : (i+1)*seq_length]
encoded_X=tokenizer.texts_to_sequences(X_sample)
train_X.append(encoded_X)
y_sample=total_data[i*seq_length + 1 : (i+1)*seq_length + 1]
encoded_y=tokenizer.texts_to_sequences(y_sample)
train_y.append(encoded_y)
print(train_X[0])
print(train_y[0])
# [[50], [38], [35], [1], [46], [48], [45], [40], [35], [33], [50], [1], [37], [51], [50], [35], [44], [32], [35], [48], [37], [1], [35], [32], [45], [45], [41], [1], [45], [36], [1], [31], [42], [39], [33], [35], [49], [1], [31], [34], [52], [35], [44], [50], [51], [48], [35], [49], [1], [39], [44], [1], [53], [45], [44], [34], [35], [48], [42], [31]]
# [[38], [35], [1], [46], [48], [45], [40], [35], [33], [50], [1], [37], [51], [50], [35], [44], [32], [35], [48], [37], [1], [35], [32], [45], [45], [41], [1], [45], [36], [1], [31], [42], [39], [33], [35], [49], [1], [31], [34], [52], [35], [44], [50], [51], [48], [35], [49], [1], [39], [44], [1], [53], [45], [44], [34], [35], [48], [42], [31], [44]]* 그런데, 우리가 사용하려는 데이터인 total_data는 앨리스 전문을 이어붙인 하나의 string이다. 이를 데이터셋으로 구성하기 위해 임의의 크기인 60으로 total_data를 자른다. 그리고 length가 60인 stirng을 sequence로 바꿔준다.
train_X=to_categorical(train_X)
train_y=to_categorical(train_y)
print('train_X의 크기(shape) : {}'.format(train_X.shape))
print('train_y의 크기(shape) : {}'.format(train_y.shape))
# train_X의 크기(shape) : (2658, 60, 57)
# train_y의 크기(shape) : (2658, 60, 57)* charRNN model에는 embedding layer가 없다. 때문에 train_X에 대해서도 one-hot encoding을 시행한다.
* one-hot encoding을 하고 나면 train_X, train_Y 모두 (2658,60,57)의 shape를 가지게 된다. 이를 그림으로 표현하면 다음과 같다.
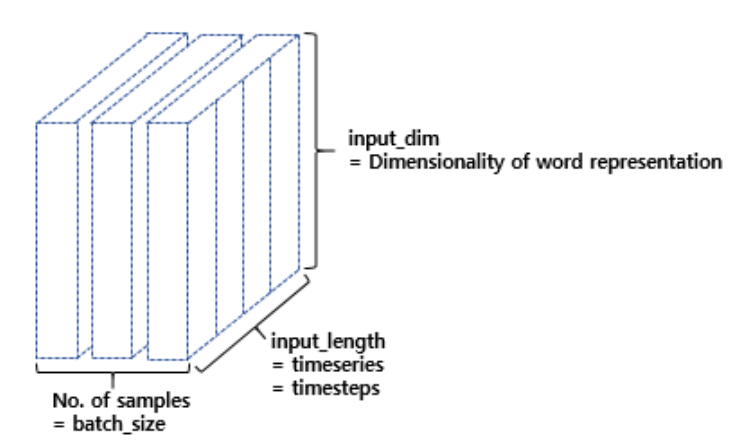
2) 모델 설계하기
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, TimeDistributed
hidden_units=256
model=Sequential()
model.add(LSTM(hidden_units, input_shape=(None, train_X.shape[2]), return_sequences=True))
model.add(LSTM(hidden_units, return_sequences=True))
model.add(TimeDistributed(Dense(vocab_size, activation='softmax')))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(train_X, train_y, epochs=80, verbose=2)
# Epoch 1/80
# 84/84 - 14s - loss: 3.0782 - accuracy: 0.1800 - 14s/epoch - 163ms/step
# Epoch 2/80
# 84/84 - 3s - loss: 2.7585 - accuracy: 0.2430 - 3s/epoch - 39ms/step
# Epoch 3/80
# 84/84 - 3s - loss: 2.3960 - accuracy: 0.3279 - 3s/epoch - 34ms/step
# 중략...
# Epoch 77/80
# 84/84 - 3s - loss: 0.2500 - accuracy: 0.9379 - 3s/epoch - 34ms/step
# Epoch 78/80
# 84/84 - 3s - loss: 0.2336 - accuracy: 0.9437 - 3s/epoch - 34ms/step
# Epoch 79/80
# 84/84 - 3s - loss: 0.2365 - accuracy: 0.9415 - 3s/epoch - 34ms/step
# Epoch 80/80
# 84/84 - 3s - loss: 0.2398 - accuracy: 0.9383 - 3s/epoch - 34ms/step
# <keras.callbacks.History at 0x7faec844ed10>* 앞서 언급한대로 charRNN은 embedding layer를 사용하지 않는다. lstm layer를 2개 사용하였고, 마지막엔 TimeDistributed()로 감싼 Dense() layer를 사용하였다. TimeDistributed()를 사용하면 매개변수로 온 layer가 이전의 RNN 혹은 LSTM layer의 timestep마다의 출력을 받을 수 있게 된다. 이를 통해 매개변수로 온 Dense layer는 매 timestep마다 예측 결과값을 softmax함수를 사용하여 출력해줄 수 있게 된다.
import random
def sentence_generator(model, length):
random_str=np.random.choice(list(tokenizer.word_index.keys())[30:]) #alphabet중에 random choice
random_num=tokenizer.word_index[random_str]
print('random한 alphabet \'{}\'부터 시작합니다.'.format(random_str))
sentence=[random_num]
for i in range(length):
current_sentence=to_categorical(sentence, num_classes=vocab_size)
current_sentence=current_sentence[np.newaxis, :, :]
predicted=np.argmax(model.predict(current_sentence)[:,-1])
sentence.append(predicted)
sentence=np.array(sentence)[np.newaxis, :]
return tokenizer.sequences_to_texts(sentence)
print(sentence_generator(model, 100))
# random한 alphabet 'i'부터 시작합니다.
# i n g t o a l i c e a g o o d s h a l l a n d a n d o f f e r a t s h e f o r t h m a d b e n o m , b e a u t i f u l s o u p ! b e a u o o t i f , s a i d t h e* 마지막으로 sentence_generator를 통해 예측 결과를 출력해보았다. 그런데 sequences_to_texts 결과를 살펴보면 단어 사이에 공백이 추가된 것을 확인할 수 있다.... 공백이 없는 문장을 사용하려면 word_index를 활용해 빈 string에 예측값을 하나하나 join시켜도 되고 여러가지 방법을 사용하면 될 것이다. 이번 포스팅에서는 크게 중요한 내용은 아니니 넘어가도록하겠다...^^;;
'Deep Learning > 자연어처리' 카테고리의 다른 글
| Sparse Representation, Dense Representation (0) | 2021.12.27 |
|---|---|
| RNN을 이용한 디코더-인코더 - Seq2Seq (0) | 2021.12.23 |
| LSTM을 사용하여 텍스트 생성하기 (0) | 2021.12.18 |
| RNN을 이용한 텍스트 생성 (0) | 2021.12.17 |
| RNN 언어 모델(RNNLM) (0) | 2021.12.17 |



