RNN을 이용한 텍스트 생성
1) RNN을 이용하여 텍스트 생성하기 * 만약 '경마장에 있는 말이 뛰고 있다', '그의 말이 법이다', '가는 말이 고와야 오는 말이 곱다' 3가지 문장을 학습하려고 한다고 가정해보자. * 이 3개의 문장
soki.tistory.com
* 앞선 포스팅에서 RNN을 사용해 텍스트를 생성하는 방법에 대해 알아보았다. 이번 포스팅에서는 LSTM을 활용하여 텍스트를 생성하는 방법에 대해 알아보겠다.
* 데이터셋을 준비하고 모델을 구성하는 것은 비슷하지만, LSTM을 사용하면 더 sequence의 처리가 가능하기 때문에 RNN과 같이 우리가 직접 생성한 6단어정도로 구성된 짧은 문장 뿐만 아니라 더 긴 문장을 훈련 시키는 것이 가능해진다.
1) 데이터셋 준비
* 데이터셋은 kaggle에 있는 뉴욕 타임즈 기사(article) 데이터를 다운로드 받아서 사용한다.
https://www.kaggle.com/aashita/nyt-comments/version/13?select=ArticlesApril2018.csv
New York Times Comments
Comments on articles published in the New York Times
www.kaggle.com
* kaggle 링크를 들어가서 2018년 자료(ArticlesApril2018.csv)를 다운로드 받으면 된다.
* 2018년 4월 기사의 headline을 데이터로 사용하겠다.
데이터셋 로드
import pandas as pd
import numpy as np
from string import punctuation
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.utils import to_categorical
from google.colab import drive
drive.mount('/gdrive')
df=pd.read_csv('/gdrive/My Drive/딥러닝을 이용한 자연어처리 입문/ArticlesApril2018.csv')
df.head()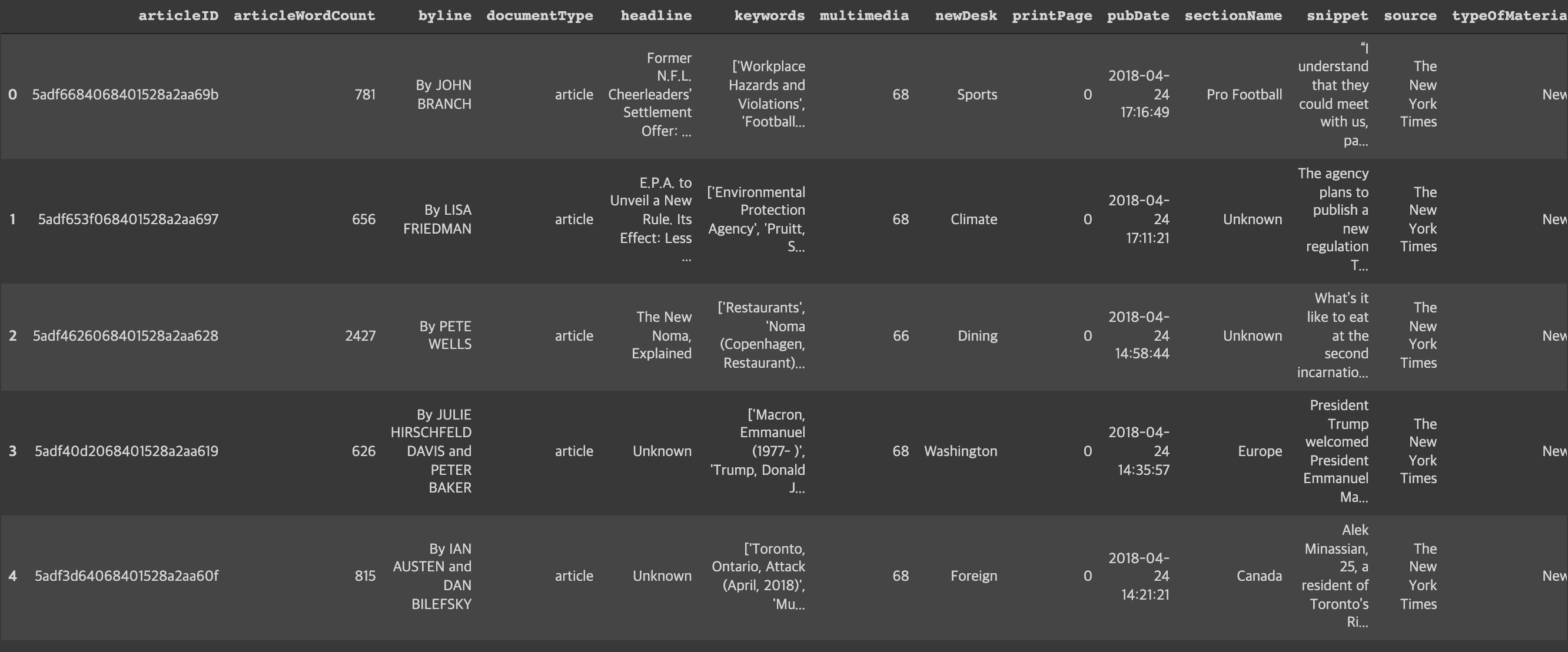
* google drive에 데이터셋 csv파일을 업로드하고, colab에 load하였다.
null값 확인
print(df['headline'].isnull().values.any())
#False
'Unknown'값 삭제
headline=[]
headline.extend(list(df.headline.values))
headline[:5]
# ['Former N.F.L. Cheerleaders’ Settlement Offer: $1 and a Meeting With Goodell',
# 'E.P.A. to Unveil a New Rule. Its Effect: Less Science in Policymaking.',
# 'The New Noma, Explained',
# 'Unknown',
# 'Unknown']* null value는 없었지만, 'Unknown'이라는 형태의 값이 존재하였다. 이렇게 raw data를 작성한 작성자들은 null 외에도 자신들만의 null value표기법을 사용할 수 있으므로 꼼꼼히 확인한다. 이 'Unknown'값을 지워주도록 하자.
len(headline)
headline=[word for word in headline if word != 'Unknown']
len(headline)
#1324
#1214* 'Unknown'이 아닌 값만 headline에 담았더니 110개의 값이 제외되었다.
구두점(punctuation) 제거 및 소문자화
#인코딩 및 구두점제거, 소문자화
def preprocessing(data):
new_data=data.encode("utf8").decode("ascii", "ignore")
return ''.join(word for word in new_data if word not in punctuation).lower()
new_headline=[preprocessing(sentence) for sentence in headline]
new_headline[:5]
# ['former nfl cheerleaders settlement offer 1 and a meeting with goodell',
# 'epa to unveil a new rule its effect less science in policymaking',
# 'the new noma explained',
# 'how a bag of texas dirt became a times tradition',
# 'is school a place for selfexpression']* 문장에서 순수한 영어 소문자 단어들만 남을 수 있도록 string.puntuation을 활용해 구두점을 제외한 alphabet만 return함과 동시에 lower()함수를 사용해 소문자로 변환한다.
훈련 데이터셋 생성
* 훈련 데이터셋을 생성할 때 맨 처음에 링크를 걸어놓은 이전 포스팅에서와 같이 '훈련 데이터셋 입니다'라는 문장이 있다면 한 단어씩 데이터를 구성한다. 예를 들면 '훈련', '훈련 데이터셋', '훈련 데이터셋 입니다'와 같이 구성할 수 있다. 이는 model이 단어를 예측하기 위해 이전에 등장한 단어를 모두 활용하기 위해서이다.
tokenizer=Tokenizer()
tokenizer.fit_on_texts(new_headline)
vocab_size=len(tokenizer.word_index)+1
vocab_size
#3494* 먼저 tokenizer 객체를 생성한 후에 tokenizer를 우리가 생성한 new_headline에 fit해준다.
* 또한 one-hot encoding을 위해 vocab size도 지정해준다. vocab size는 one-hot encoding시 0 자리를 위해 word 개수+1 만큼의 크기로 할당한다.
sentences=[]
for sentence in new_headline:
encoded=tokenizer.texts_to_sequences([sentence])[0]
for i in range(1, len(encoded)):
sentences.append(encoded[:i+1])
sentences[:11]
[[99, 269], # former nfl
[99, 269, 371], # former nfl cheerleaders
[99, 269, 371, 1115], # former nfl cheerleaders settlement
[99, 269, 371, 1115, 582], # former nfl cheerleaders settlement offer
[99, 269, 371, 1115, 582, 52], # 'former nfl cheerleaders settlement offer 1
[99, 269, 371, 1115, 582, 52, 7], # former nfl cheerleaders settlement offer 1 and
[99, 269, 371, 1115, 582, 52, 7, 2], # ...
[99, 269, 371, 1115, 582, 52, 7, 2, 372],
[99, 269, 371, 1115, 582, 52, 7, 2, 372, 10],
[99, 269, 371, 1115, 582, 52, 7, 2, 372, 10, 1116],
[100, 3]] # epa to에 해당되며 두번째 문장이 시작됨.패딩 작업
max_len=max(len(l) for l in sentences)
sequences=pad_sequences(sentences, maxlen=max_len, padding='pre')
sequences[0]
# array([ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
# 0, 0, 0, 0, 0, 0, 0, 0, 0, 99, 269], dtype=int32)* sentences안에 있는 문장들이 길이가 모두 다르기 때문에 길이를 맞춰주기 위해 padding 작업을 시행하였다.
X, y split 작업, y 데이터 one-hot encoding
X=sequences[:,:-1]
y=sequences[:,-1]
y=to_categorical(y, num_classes=vocab_size)
print(X[0])
print(y[0])
# [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 99]
# [0. 0. 0. ... 0. 0. 0.]* X, y 데이터를 split해주고, y 데이터를 one-hot encoding해주었다.
2) 모델 설계
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense
embedding_dim=10
hidden_units=128
model=Sequential()
model.add(Embedding(vocab_size, embedding_dim))
model.add(LSTM(hidden_units))
model.add(Dense(vocab_size, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(X, y, epochs=200, verbose=2)
# Epoch 1/200
# 244/244 - 11s - loss: 7.6465 - accuracy: 0.0263 - 11s/epoch - 44ms/step
# Epoch 2/200
# 244/244 - 3s - loss: 7.1167 - accuracy: 0.0323 - 3s/epoch - 12ms/step
# Epoch 3/200
# 244/244 - 3s - loss: 6.9753 - accuracy: 0.0342 - 3s/epoch - 12ms/step
# 중략...
# 244/244 - 3s - loss: 0.2656 - accuracy: 0.9161 - 3s/epoch - 11ms/step
# Epoch 197/200
# 244/244 - 3s - loss: 0.2656 - accuracy: 0.9168 - 3s/epoch - 11ms/step
# Epoch 198/200
# 244/244 - 3s - loss: 0.2654 - accuracy: 0.9152 - 3s/epoch - 12ms/step
# Epoch 199/200
# 244/244 - 3s - loss: 0.2690 - accuracy: 0.9153 - 3s/epoch - 11ms/step
# Epoch 200/200
# 244/244 - 3s - loss: 0.2715 - accuracy: 0.9158 - 3s/epoch - 12ms/step
# <keras.callbacks.History at 0x7faed0183f90>* model은 embedding, 128개의 unit을 가진 lstm layer, dense layer로 구성하였다.
3) 텍스트 생성하기
def sentence_generator(model, tokenizer, current_word, max_len, n):
init_word=current_word
sentence=''
for _ in range(n):
encoded=tokenizer.texts_to_sequences([current_word])
encoded=pad_sequences(encoded, maxlen=max_len, padding='pre')
predicted=model.predict(encoded)
predicted=np.argmax(predicted, axis=1)
for word, index in tokenizer.word_index.items():
if index==predicted:
break
current_word=current_word+' '+word
sentence=sentence+' '+word
sentence=init_word+sentence
return sentence
print(sentence_generator(model, tokenizer, 'i', max_len, 10))
# i cant jump ship from facebook yet my was was fired* 모델을 사용하여 텍스트를 생성하는 함수를 생성하고, ' i ' 단어가 주어졌을 때 10개의 단어를 생성하게 시켜보았다.
* was가 두 번 나왔고, 문장이 매끄럽지는 못 하지만 어느정도는 개연성 있는 문장이 생성되었다.
6) RNN을 이용한 텍스트 생성(Text Generation using RNN)
이번 챕터에서는 다 대 일(many-to-one) 구조의 RNN을 사용하여 문맥을 반영해서 텍스트를 생성하는 모델을 만들어봅시다. ##**1. RNN을 이용하여 텍스트 생 ...
wikidocs.net
'Deep Learning > 자연어처리' 카테고리의 다른 글
| RNN을 이용한 디코더-인코더 - Seq2Seq (0) | 2021.12.23 |
|---|---|
| 글자 단위 RNN(Char RNN) (0) | 2021.12.18 |
| RNN을 이용한 텍스트 생성 (0) | 2021.12.17 |
| RNN 언어 모델(RNNLM) (0) | 2021.12.17 |
| 피드포워드 신경망 언어 모델(NNLM) (0) | 2021.12.16 |



