확률과 언어모델
word2vec 을 확률 관점에서 바라보기
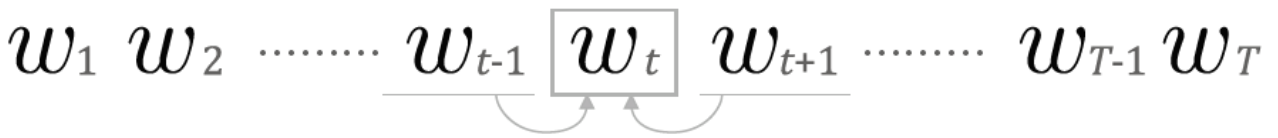
* CBOW 모델에서 t 번째 단어가 target이고 양 옆의 단어가 context라면 target 단어에 $w_t$가 올 확률은 아래와 같다.
$P(w_t | w_{t-1}, w_{t+1})$
* 이렇게 CBOW 모델은 사후확률을 추측한다.
* 만약 context를 설정하는 윈도우를 target의 왼쪽 두 단어로 생각하면 확률은 다음과 같다.
$P(w_t | w_{t-2}, w_{t-1})$
* 그리고 이에 대한 손실함수는 아래와 같다.
$L = - log P(w_t | w_{t-2}, w_{t-1})$
* 이렇게 주어진 context에서 target을 추론하는 모델은 다음에 설명할 언어모델에서 사용된다.
언어 모델(Language Model)
* 언어모델은 문장 시퀀스에 대해 발생 확률을 부여한다.
ex) 'you say goodbye'는 0.092를, 'you say good die'에는 0.0000000000000032를 부여
* 음성인식 시스템의 경우 입력된 음성으로부터 몇 개의 문장 후보를 생성한다. 그리고 후보들에 대한 발생 확률을 계산하고 확률에 근거해 자연스러운 문장 순서를 매긴다.
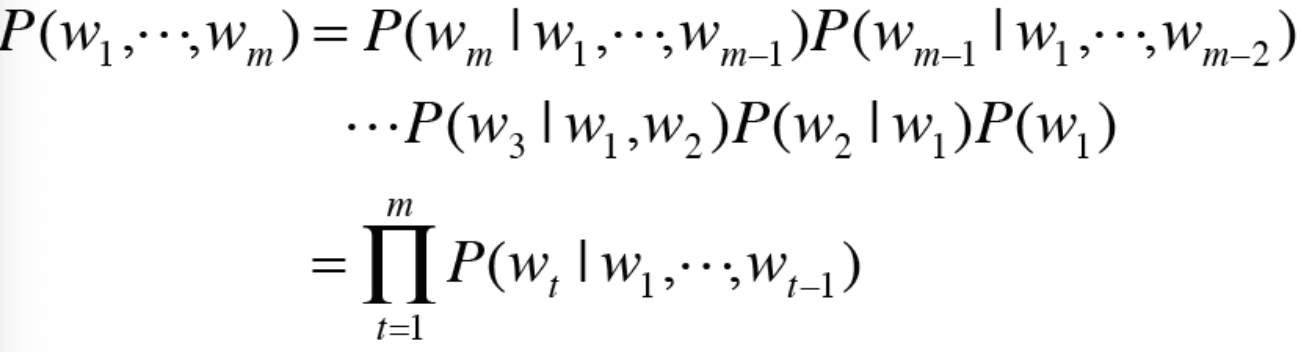
* 동시발생확률은 사후 확률들의 곱으로 표현할 수 있기 때문에 문장 시퀀스에 대한 발생 확률은 위와 같이 계산할 수 있다.
* 동시발생확률이 사후 확률들의 곱으로 표현된다는 것은 아래와 같이 증명할 수 있다.
$P(A, B) = P(A|B)P(B) = P(B|A) P(A)$
* 동시발생확률을 해석해보자면 B가 발생할 확률 곱하기 B가 발생한 후 A가 발생할 확률이라고 할 수 있다.
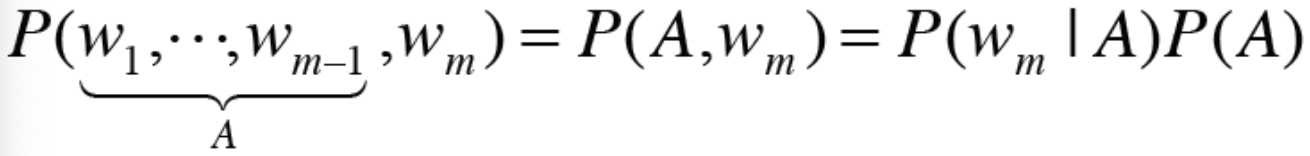
* 위에서 설명한 곱셈정리를 문장 시퀀스에 대한 발생확률에 대입해보면 위와 같이 쓸 수 있다. P(A)는 또한 아래와 같이 계산된다.
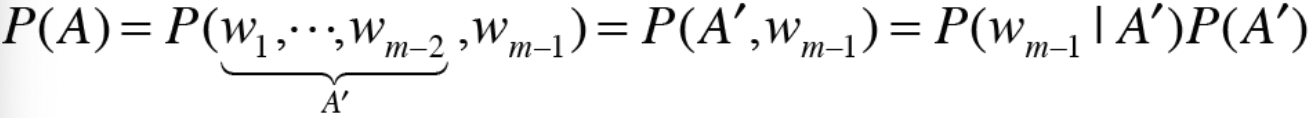
* 이렇게 계속 반복하다보면 최초에 봤던 식을 도출할 수 있다.
* 이렇게 동시확률 $P(w_1, ... , w_m)$은 사후 확률의 총곱인 $\prod P(w_t | w_1 , ... , w_m)$ 로 표현할 수 있다는 것을 알았다. 그런데 식을 자세히 보면 target의 발생확률은 target의 왼쪽에 있는 모든 단어의 사후확률로 표현되어 있는 것을 알 수 있다. 그림으로 보면 아래와 같다.
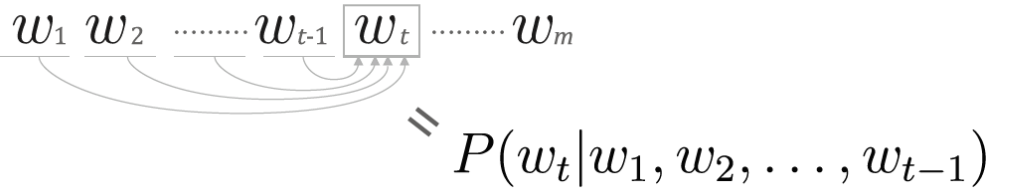
* 결국 언어모델의 목표(문장 시퀀스가 주어졌을 때 단어들의 동시발생확률을 구하는 것)는 해당 단어 이전의 단어들이 발생했을 때 target 단어가 발생할 확률을 구하는 것을 통해 달성할 수 있다는 것을 알았다.
CBOW 모델을 언어 모델로?
* CBOW 모델을 언어 모델에 적용하기 위해서는 어떻게 해야 할까?
$P(w_1, ... , w_m) = \prod_{t=1}^m P(w_t | w_1, ... , w_{t-1}) \approx \prod_{t=1}^m P(w_t | w_{t-2}, w_{t-1})$
* 위와 같이 왼쪽의 n개의 단어에 대한 사후확률로 근사하여 계산할 수 있다.
* 하지만 설정한 n개의 단어 안에 target을 위해 필요한 정보가 없다면 제대로 된 예측이 불가능할 것이다.
* 또한 CBOW 모델은 BoW모델이기 때문에 context의 순서를 고려하지 않는다.
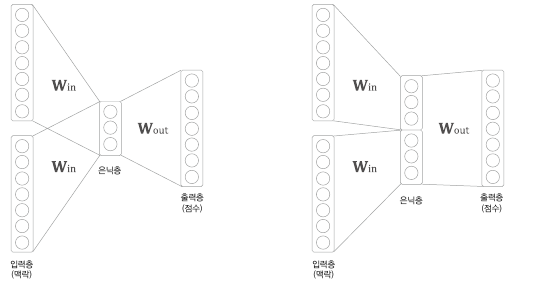
* 왼쪽이 CBOW모델인데, 은닉층에 입력되는 과정에서 순서가 고려되지 않는 것을 알 수 있다. 그렇다면 CBOW와 비슷하지만, context의 순서를 고려하는 모델은 없을까?
* 오른쪽은 Neural Probabilistic Language Model인데, 은닉층에 따로 context를 입력해 concate하는 방식을 사용하여 순서를 고려하는 것을 볼 수 있다.
* 그렇다면 오른쪽 모델을 사용하면 되는가? 오른쪽 모델은 순서를 고려하는 장점이 있지만 은닉 노드가 많아지기 때문에 가중치의 개수도 많아진다는 단점이 있다.
* 이 NPLM의 단점을 보완할 수 있는 모델이 RNN을 사용한 언어모델이다.
RNN(Recurrent Neural Network)
순환하는 신경망
* RNN은 데이터가 순환 경로(닫힌 경로)를 계속 순환하며 최신 데이터로 갱신되는 신경망을 뜻한다.
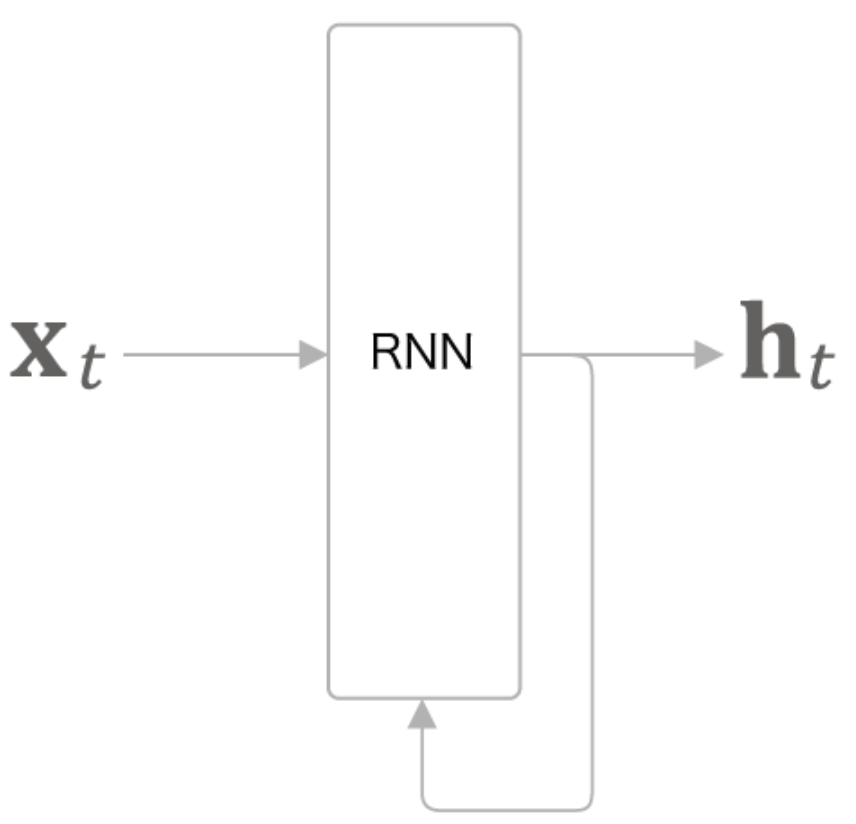
순환구조 펼치기

* 순환구조를 시각적으로 보기 편하게 time step에 따라 펼쳐 그리면 오른쪽 과 같다.
* 출력 $h_t$는 다음과 같이 계산된다.
$h_t = tanh(h_{t-1} W_h + x_t W_x + b)$
* h는 hidden state의 약자이다.
BPTT(Backpropagation Through Time)
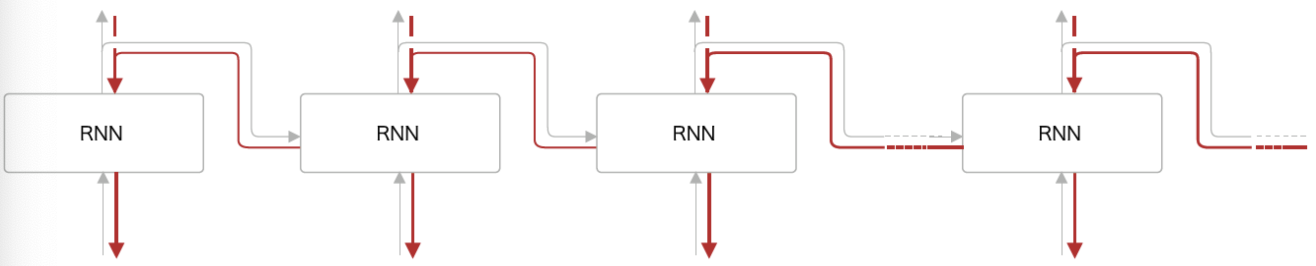
* time step에 따라 backpropagation이 이뤄지기 때문에 RNN의 backpropagation 과정을 BPTT라고 부른다.
* 문장 시퀀스가 길어짐에 따라 역전파되는 기울기가 작아지는 문제(Gradient Vanishing), 역전파를 위해 저장하는 기울기로 인한 메모리 부족 문제 등이 발생하는데 이는 다음에 설명할 Truncated BPTT를 통해 해결할 수 있다.
Truncated BPTT
* 순전파는 그대로 시행하고 역전파시에만 일정 time step 단위로 신경망을 끊어 학습한다.

* 순전파의 연결은 끊기지 않기 때문에 데이터가 순서대로 입력되어야 한다. 미니배치에서 random한 데이터를 sampling해 입력하는 것과는 다르다. 이는 추후 더 자세히 설명하겠다.
Truncated BPTT의 미니배치 학습
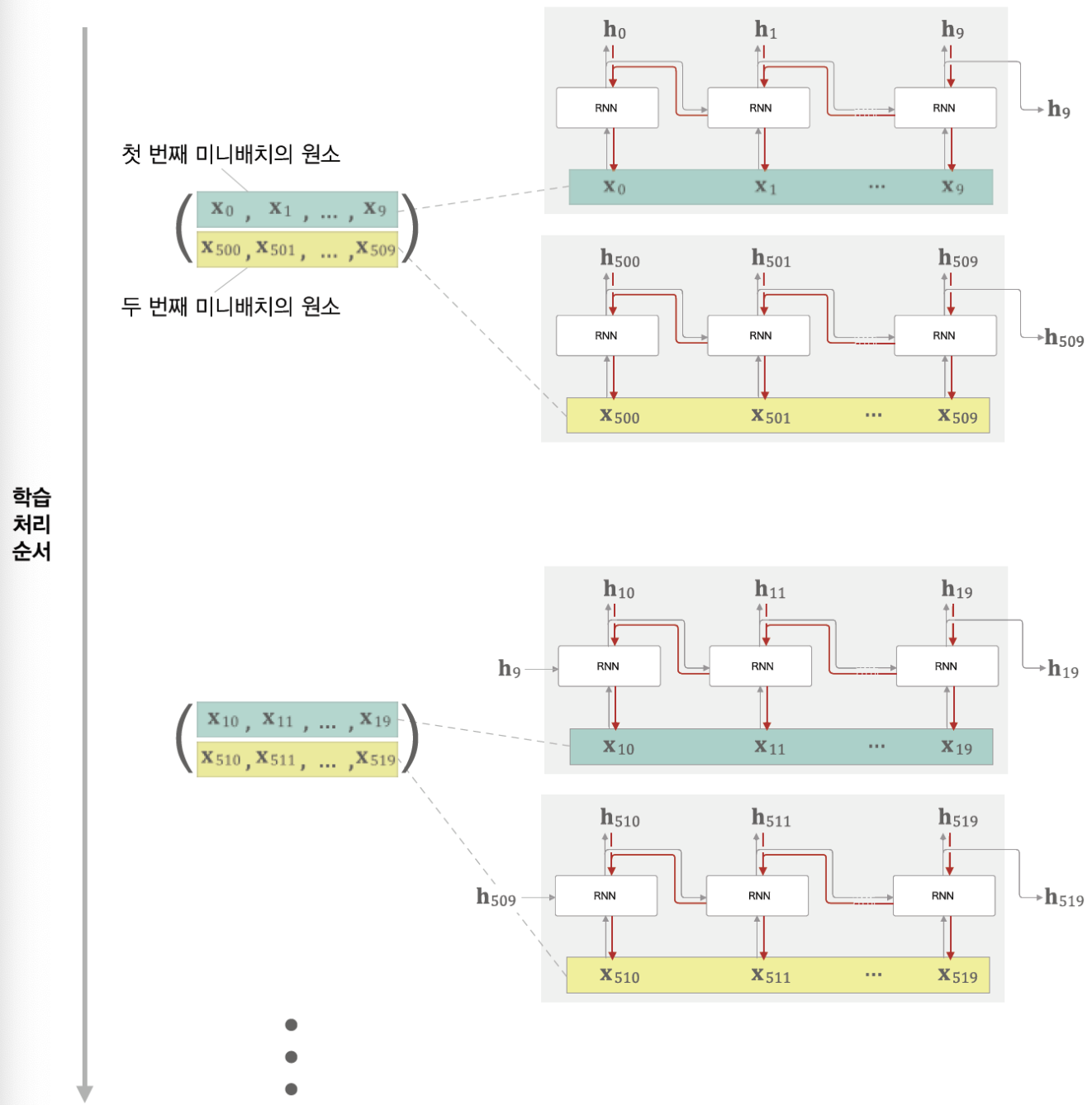
* 길이가 1000인 문장을 10개 단위로 잘라 BPTT를 시행하고 미니배치가 2 단위로 이뤄진다고 해보자.
* 첫 번째 epoch에서는 첫 번째 배치에는 $x_0 ~ x_9$까지, 두 번째 배치에는 $x_500 ~ x_509$가 입력된다.
* 다음 epoch에서는 random한 10개의 time step이 아닌 첫 번째 epoch에 입력된 time step의 다음 time step부터 입력되어야 한다.
* 만약 마지막 단어까지 입력되었다면 다시 처음부터 최초 입력 단어 전까지 입력한다.
RNN 구현
Time RNN 계층
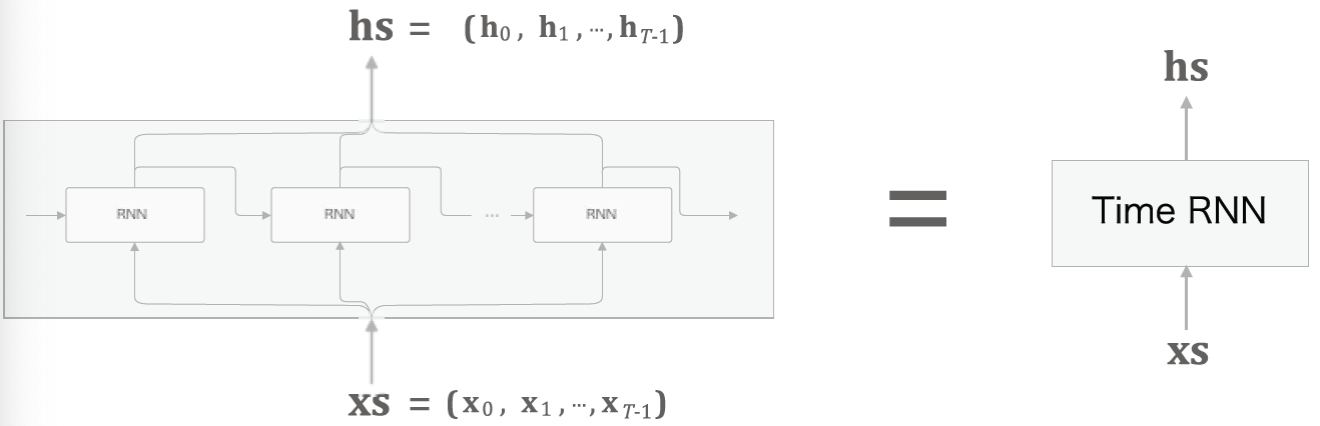
* 일정한 고정 길이의 sequence를 입력 받으면 고정 길이의 sequence를 출력하는 여러 개의 RNN 계층들로 구성된 구조를 time RNN 계층이라고 하자. Time RNN 계층은 공식적인 명칭은 아니며 편의를 위해 임의로 정한 명명규칙이다.
RNN 계층 구현
$h_t = tanh(h_{t-1} W_h + x_t W_x + b)$
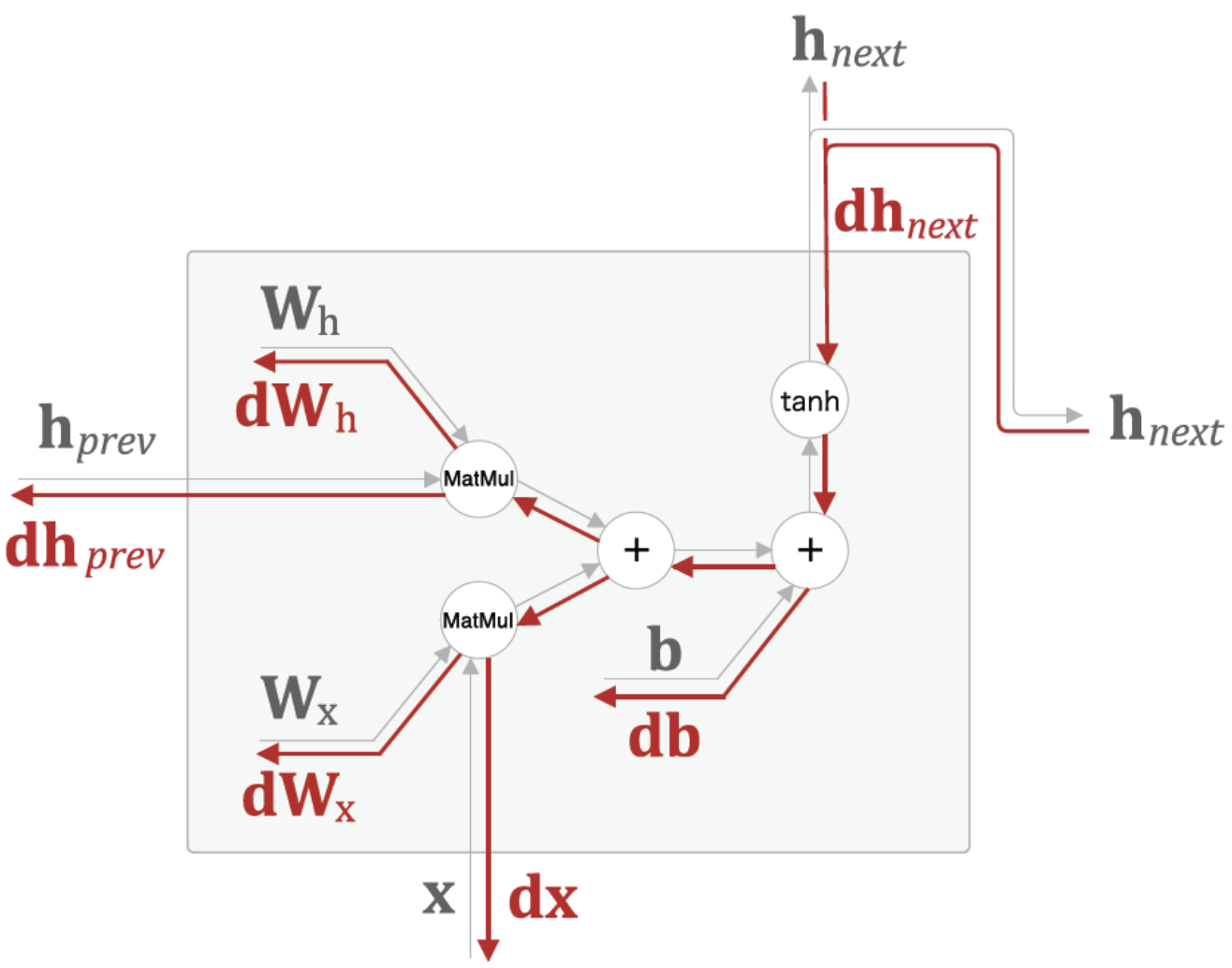
class RNN:
def __init__(self, Wx, Wh, b):
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.cache = None
def forward(self, x, h_prev):
Wx, Wh, b = self.params
t = np.dot(h_prev, Wh) + np.dot(x, Wx) + b
h_next = np.tanh(t)
self.cache = (x, h_prev, h_next)
return h_next
def backward(self, dh_next):
Wx, Wh, b = self.params
x, h_prev, h_next = self.cache
dt = dh_next * (1 - h_next ** 2)
db = np.sum(dt, axis=0)
dWh = np.dot(h_prev.T, dt)
dh_prev = np.dot(dt, Wh.T)
dWx = np.dot(x.T, dt)
dx = np.dot(dt, Wx.T)
self.grads[0][...] = dWx
self.grads[1][...] = dWh
self.grads[2][...] = db
return dx, dh_prev
TIme RNN 계층 구현
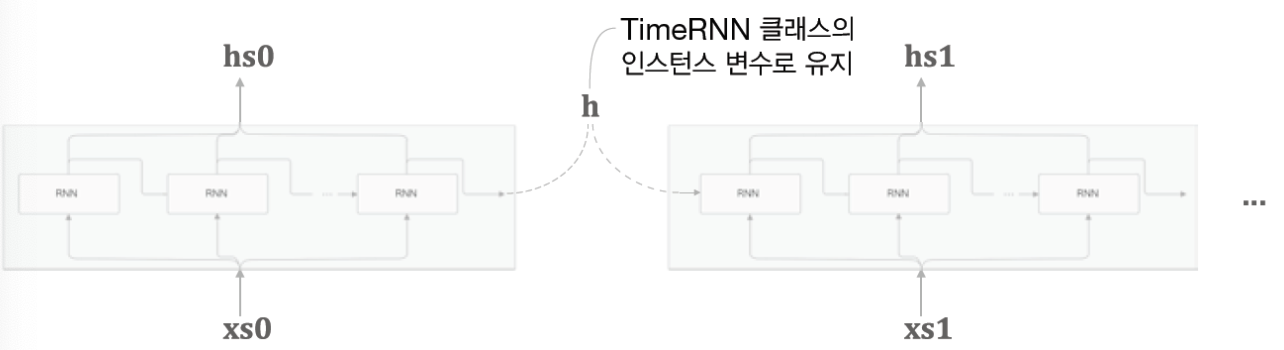
* hidden state h를 인스턴트 변수로 유지해서 RNN 계층이 아니라 Time RNN계층에서 관리하도록 하자. 이를 통해 RNN계층은 hidden state를 다음 time step의 RNN cell에 인계하지 않고 Time RNN 층의 hidden state만 가져다 쓰고 갱신하면 된다.
class TimeRNN:
def __init__(self, Wx, Wh, b, stateful=False):
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.layers = None # 다수의 RNN 계층을 리스트로 저장
self.h, self.dh = None, None
self.stateful = stateful # True일 경우 Time RNN 계층이 hidden state를 유지, 다음 iteration의 배치에 넘겨줌
def forward(self, xs):
Wx, Wh, b = self.params
N, T, D = xs.shape # 미니배치 크기, time steps, 입력 벡터 차원의 수
D, H = Wx.shape
self.layers = []
hs = np.empty((N, T, H), dtype='f')
if not self.stateful or self.h is None:
self.h = np.zeros((N, H), dtype='f')
for t in range(T): # t개의 RNN layer 생성
layer = RNN(*self.params)
self.h = layer.forward(xs[:, t, :], self.h)
hs[:, t, :] = self.h
self.layers.append(layer)
return hs
def backward(self, dhs):
Wx, Wh, b = self.params
N, T, H = dhs.shape
D, H = Wx.shape
dxs = np.empty((N, T, D), dtype='f')
dh = 0
grads = [0, 0, 0]
for t in reversed(range(T)):
layer = self.layers[t]
dx, dh = layer.backward(dhs[:, t, :] + dh)
dxs[:, t, :] = dx
for i, grad in enumerate(layer.grads):
grads[i] += grad
for i, grad in enumerate(grads):
self.grads[i][...] = grad
self.dh = dh
return dxs
def set_state(self, h):
self.h = h
def reset_state(self):
self.h = None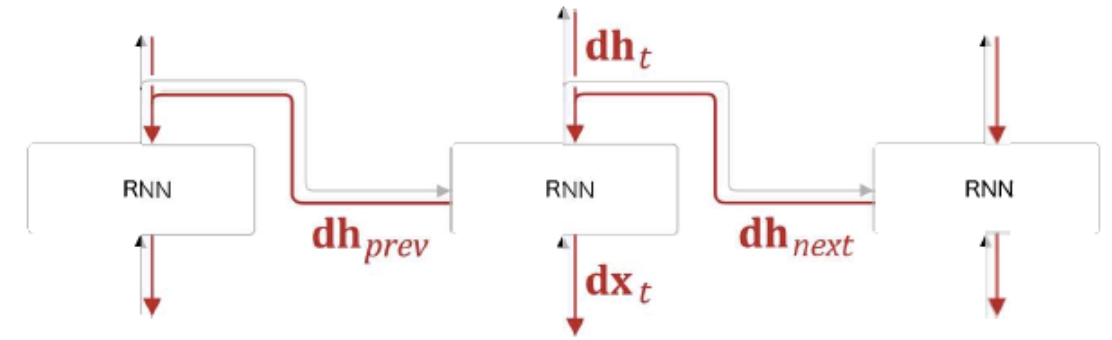
* time step t의 RNN계층에 전해지는 기울기는 이전 Time RNN의 timestep t의 기울기와 t+1의 RNN계층의 기울기 이렇게 2가지이다. 그리고 이를 합산한 기울기가 최종적으로 전해진다.
시계열 데이터 처리 계층 구현
RNNLM(RNN Language Model)의 전체 그림
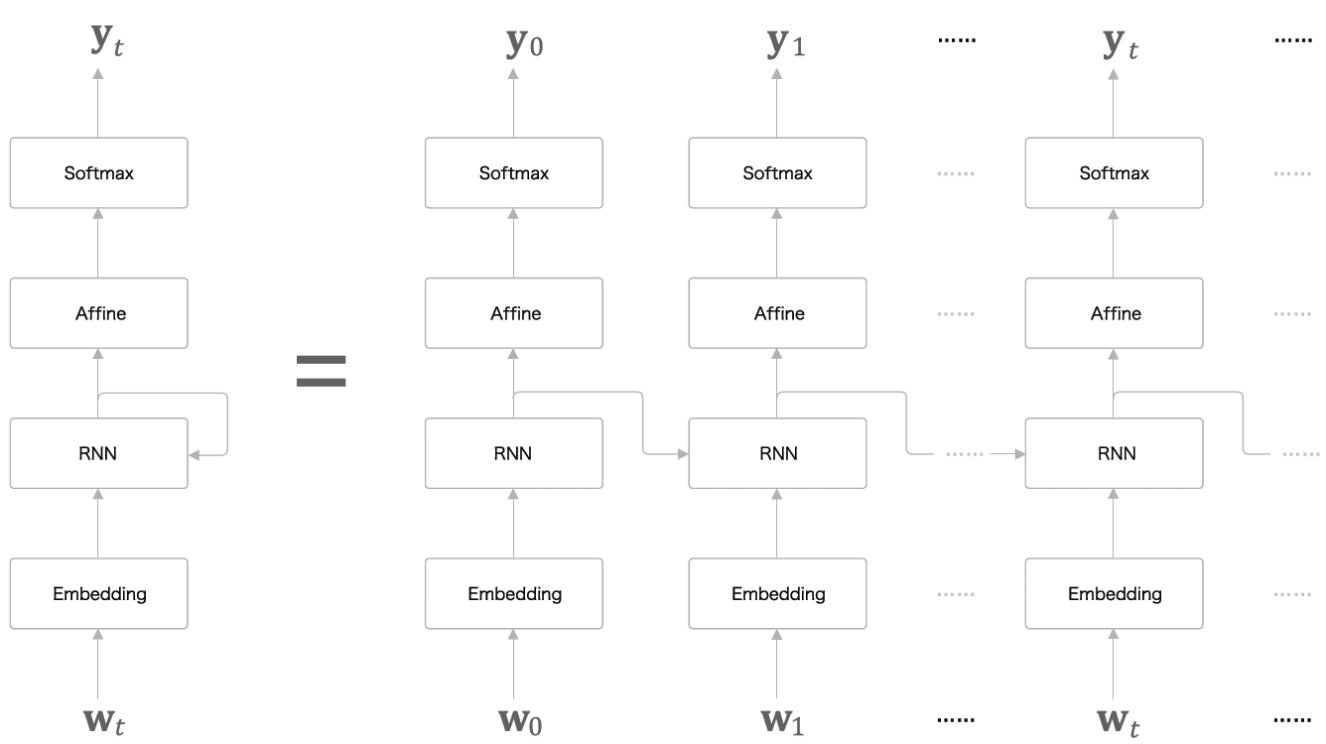
* Embedding 계층에서는 단어가 입력되면 분산 표현 (단어 벡터) 로 변환된다. 이 분산 표현은 RNN에 입력된다.
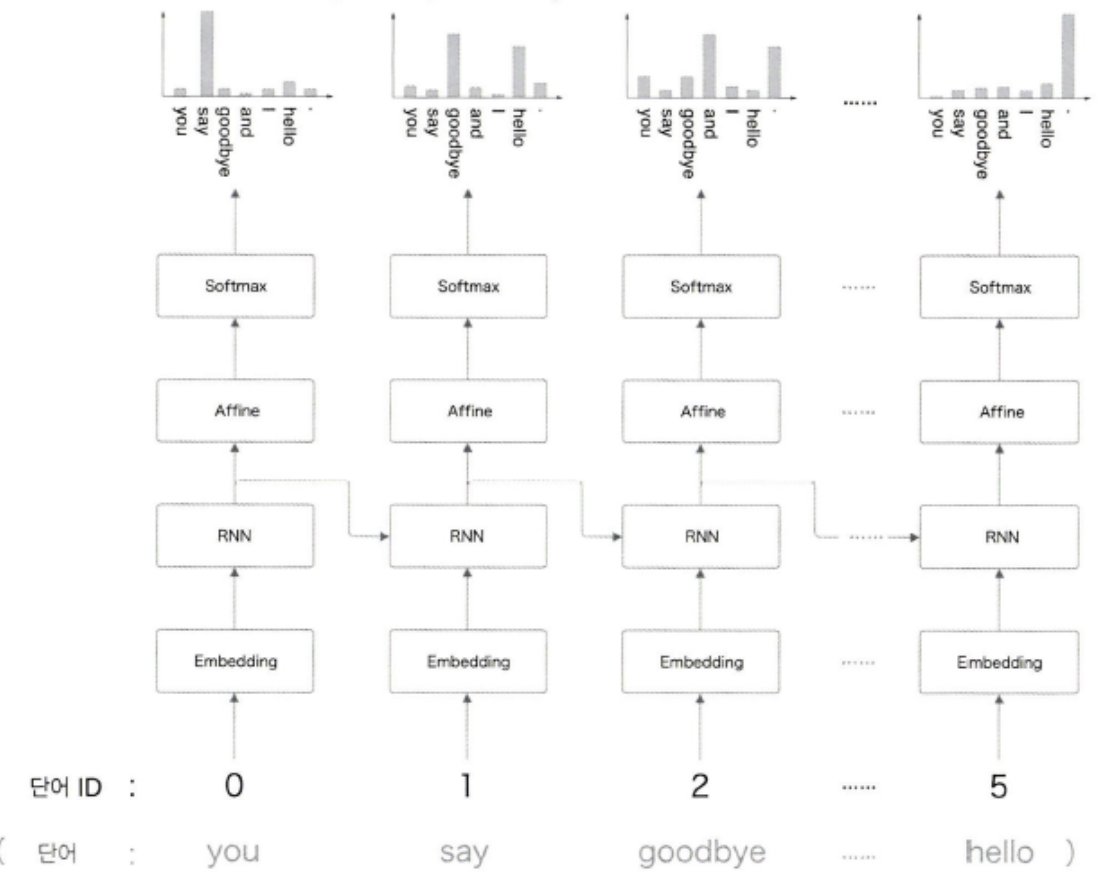
* you say good bye를 RNNLM에 입력한 결과이다.
* RNN을 사용하기 때문에 과거에 입력된 단어들에 대한 정보가 hidden state에 담겨진다. 이 덕분에 앞서 입력된 단어를 모두 고려하여 다음에 올 단어를 예측하는 것이 가능하다.
Time 계층 구현
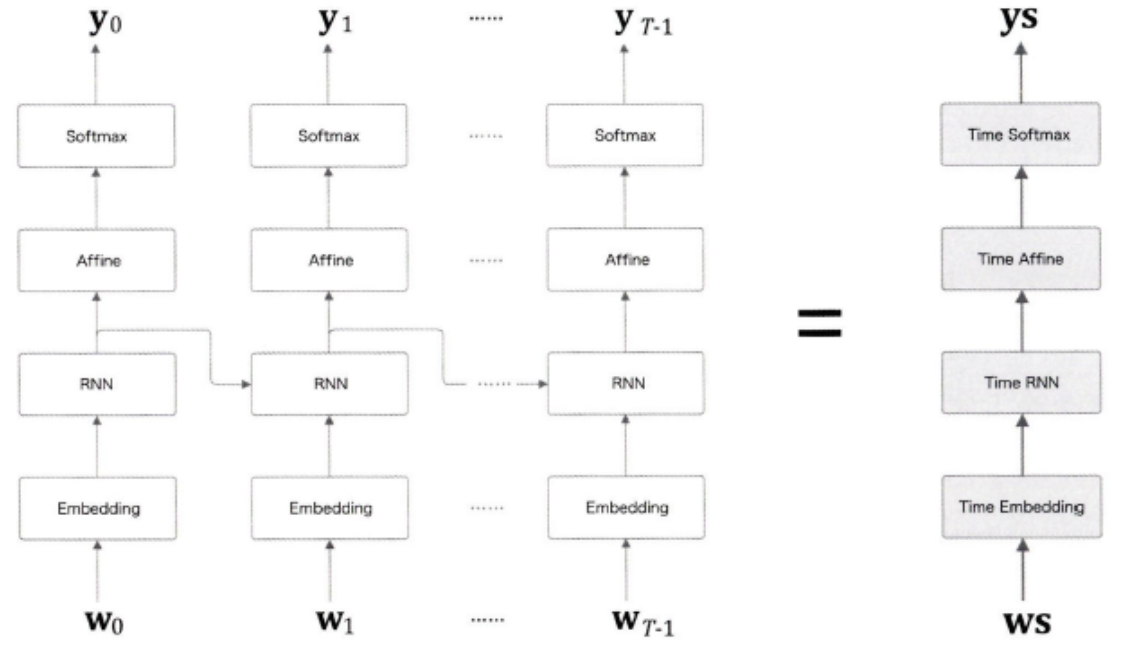
* Time Embedding, Time RNN, Time Affine, Time Softmax를 모두 한꺼번에 처리하는 신경망 계층을 Time XX계층이라고 하자.
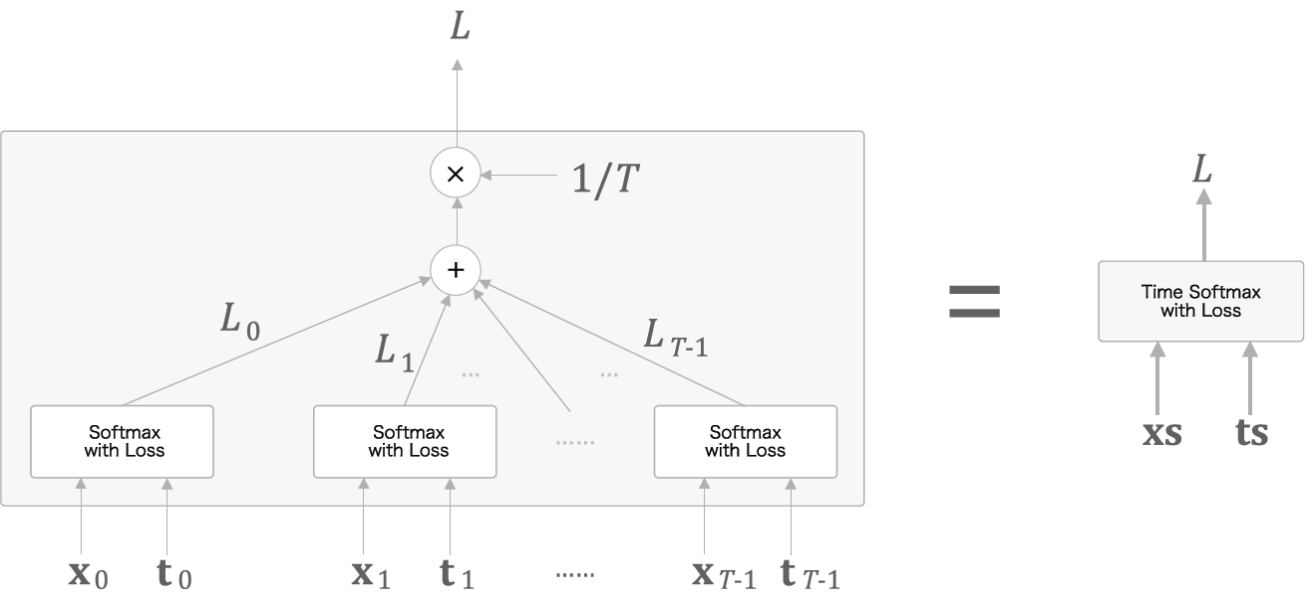
* softmax의 경우 cross entropy error까지 한 번에 구하는 softmax with loss 계층으로 구현하였다.
* loss의 경우 time step마다 계산된 loss를 모두 더해 평균하여 구한다.
* 미니배치의 경우 N개의 데이터가 있을 때 N개의 데이터의 총 손실 L들을 모두 더하여 평균한 loss를 데이터들의 손실로 사용한다.
RNNLM 학습과 평가
RNNLM 구현
import sys
sys.path.append('..')
import numpy as np
from common.time_layers import *
class SimpleRnnlm:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
# 가중치 초기화
embed_W = (rn(V, D) / 100).astype('f')
rnn_Wx = (rn(D, H) / np.sqrt(D)).astype('f')
rnn_Wh = (rn(H, H) / np.sqrt(H)).astype('f')
rnn_b = np.zeros(H).astype('f')
affine_W = (rn(H, V) / np.sqrt(H)).astype('f')
affine_b = np.zeros(V).astype('f')
# 계층 생성
self.layers = [
TimeEmbedding(embed_W),
TimeRNN(rnn_Wx, rnn_Wh, rnn_b, stateful=True),
TimeAffine(affine_W, affine_b)
]
self.loss_layer = TimeSoftmaxWithLoss()
self.rnn_layer = self.layers[1]
# 모든 가중치와 기울기를 리스트에 모은다.
self.params, self.grads = [], []
for layer in self.layers:
self.params += layer.params
self.grads += layer.grads
def forward(self, xs, ts):
for layer in self.layers:
xs = layer.forward(xs)
loss = self.loss_layer.forward(xs, ts)
return loss
def backward(self, dout=1):
dout = self.loss_layer.backward(dout)
for layer in reversed(self.layers):
dout = layer.backward(dout)
return dout
def reset_state(self):
self.rnn_layer.reset_state()* RNN 계층의 상태는 class 내부에서 관리한다.
* __init__ 메소드에서는 Truncated BPTT로 학습한다고 가정하고 Time RNN계층의 stateful을 True로 설정하였다.
* initializer로는 Xavier initializer를 사용하였다.
언어 모델의 평가
* 언어 모델은 과거에 입력된 단어들로부터 다음에 출현할 단어의 확률분포를 출력한다.
* 이 때 예측 성능의 평가 지표로서 perplexity를 자주 이용한다. 데이터 수가 1개라면 perplexity는 확률을 역수로 구할 수 있다.
* 예를 들어 you say goodbye and I say hello라는 문장 시퀀스가 주어졌다고 가정해보자.

* you가 주어졌을 때 만약 정답이 say라면 모델 1은 say를 0.8의 확률로 예측, 모델 2는 say를 0.2의 확률로 예측했다고 할 수 있다.
* 모델 1의 perplexity는 1/0.8 = 1.25이고, 모델 2의 perplexity는 1/0.2로 5가 된다. perplexity는 낮을 수록 좋기 때문에 모델 1이 더 우수하다고 판단할 수 있다.
* perplexity는 예측의 분기 수를 나타낸다고 해석할 수 있다. 예를 들어 모델 1은 1.25 즉, 1개의 후보를 출력하였고, 모델 5는 5개의 후보를 출력하였다고 해석할 수 있는 것이다.
* 그럼 이를 일반화 하여 데이터가 여러개일 때의 perplexity를 구해보자.
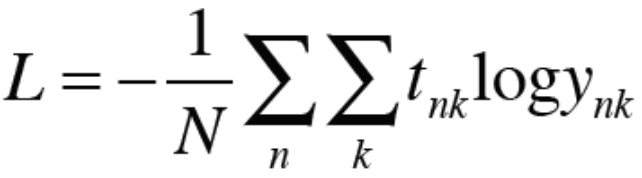
* N은 데이터의 총개수이다. $t_n$은 one-hot vector로 나타낸 정답 레이블이며, $t_nk$는 n개째 데이터의 k번째 값을 의미한다. $y_nk$는 확률분포를 나타낸다.
* 이렇게 구한 L을 다음과 같은 식에 대입해면 perplexity가 된다.
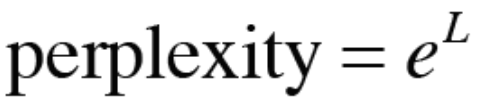
* 이렇게 구한 perplexity는 기하평균 분기수라고도 한다.
RNNLM의 학습 코드
# coding: utf-8
import sys
sys.path.append('..')
import matplotlib.pyplot as plt
import numpy as np
from common.optimizer import SGD
from dataset import ptb
from simple_rnnlm import SimpleRnnlm
# 하이퍼파라미터 설정
batch_size = 10
wordvec_size = 100
hidden_size = 100 # RNN의 은닉 상태 벡터의 원소 수
time_size = 5 # Truncated BPTT가 한 번에 펼치는 시간 크기
lr = 0.1
max_epoch = 100
# 학습 데이터 읽기(전체 중 1000개만)
corpus, word_to_id, id_to_word = ptb.load_data('train')
corpus_size = 1000
corpus = corpus[:corpus_size]
vocab_size = int(max(corpus) + 1)
xs = corpus[:-1] # 입력
ts = corpus[1:] # 출력(정답 레이블)
data_size = len(xs)
print('말뭉치 크기: %d, 어휘 수: %d' % (corpus_size, vocab_size))
# 학습 시 사용하는 변수
max_iters = data_size // (batch_size * time_size)
time_idx = 0
total_loss = 0
loss_count = 0
ppl_list = []
# 모델 생성
model = SimpleRnnlm(vocab_size, wordvec_size, hidden_size)
optimizer = SGD(lr)
# 미니배치의 각 샘플의 읽기 시작 위치를 계산
jump = (corpus_size - 1) // batch_size
offsets = [i * jump for i in range(batch_size)] # 데이터셋을 읽기 시작한 위치를 offsets에 저장
for epoch in range(max_epoch):
for iter in range(max_iters):
# 미니배치 취득
batch_x = np.empty((batch_size, time_size), dtype='i')
batch_t = np.empty((batch_size, time_size), dtype='i')
for t in range(time_size):
for i, offset in enumerate(offsets):
# offset부터 데이터를 읽음
batch_x[i, t] = xs[(offset + time_idx) % data_size]
batch_t[i, t] = ts[(offset + time_idx) % data_size]
time_idx += 1
# 기울기를 구하여 매개변수 갱신
loss = model.forward(batch_x, batch_t)
model.backward()
optimizer.update(model.params, model.grads)
total_loss += loss
loss_count += 1
# 에폭마다 퍼플렉서티 평가
ppl = np.exp(total_loss / loss_count)
print('| 에폭 %d | 퍼플렉서티 %.2f'
% (epoch+1, ppl))
ppl_list.append(float(ppl))
total_loss, loss_count = 0, 0
# 그래프 그리기
x = np.arange(len(ppl_list))
plt.plot(x, ppl_list, label='train')
plt.xlabel('epochs')
plt.ylabel('perplexity')
plt.show()* train해서 perplexity를 출력한 결과 아래와 같은 그래프가 도출된다.
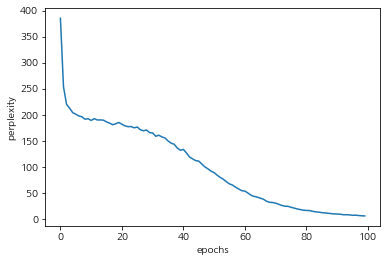
* 100 epochs에 도달하면 peplexity가 1정도에 수렴하는 것을 볼 수 있다.
'Deep Learning > 밑바닥부터 시작하는 딥러닝' 카테고리의 다른 글
| RNN을 사용한 문장 생성 (0) | 2022.02.18 |
|---|---|
| 게이트가 추가된 RNN (0) | 2022.02.10 |
| word2vec 속도개선 (0) | 2022.02.10 |
| Word2Vec (0) | 2022.02.03 |
| 딥러닝 등장 이전의 자연어와 단어의 분산 표현 (0) | 2022.02.01 |



