순환 신경망(RNN, Recurrent Neural Network)
* Feed Forward Neural Network에서는 input value가 activation function을 거치고 그 결과 값이 다시 다음 hidden layer의 input으로 들어가며 데이터가 한 방향으로만 흐르는 특징을 보여준다. 대표적으로 DNN, CNN등이 그러하다.

* 반면 RNN은 데이터가 한 방향으로만 흐르지 않는다. activation function을 거친 값이 다음 hidden layer의 input이 되기도 하고 혹은 동시에 곧바로 output layer로 향하기도 한다.
* 그림은 편향 b를 생략하고 입력 vector $x_t$, 출력 vector $y_t$만 표시한 그림이다. 위 cell이라고 표시한 부분이 RNN연산이 이뤄지는 부분이며 이전 시점 t-1의 결과값을 현재 시점 t에게 넘겨주는 것과 output layer에게 넘겨주는 역할을 한다.
* input이 입력된 후 반복해서 cell 이라고 부르는 노드에서 연산이 이뤄진다. 현재 시점 t의 결과 값은 이전 시점 t-1, t-2, ... 의 결과값들에 대한 정보를 담고 있기 때문에 해당 node를 memory cell이라고 부른다. 그리고 이 시점 t의 결과값을 $h_t$라고 표기하고 hidden state라고 부른다.
RNN에 대한 수식 정의

* 은닉층 출력에 사용되는 activation function이 tanh이라고 가정했을 때, 은닉층과 출력층에 대한 수식은 다음과 같이 정의될 수 있다.
* 은닉층 : $h_t = tanh(W_x x_t + W_h h_{t-1} + b), b$는 편향
* 출력층 : $y_t = f(W_y h_t + b)$
* 은닉층에는 tanh 외에도 ReLU가 사용될 수도 있다.
* 출력층의 경우 이진 분류 값을 얻기 위해서는 sigmoid를, 다양한 카테고리 중 선택을 해야하는 경우라면 softmax를 사용할 수 있다.
Keras로 RNN 구현하기
기본 RNN 코드
model.add(SimpleRNN(hidden_size, input_shape=(timesteps, input_dim)))
입력 tensor

* hidden_size : 은닉 상태의 크기를 정의하는 값이다. 메모리 셀이 다음 시점의 메모리 셀과 출력층으로 보내는 값의 크기라고 볼 수 있다.
* timesteps : input_length와 동일하다. 어느 정도 길이의 문장이(단어 vector 몇 개가) input으로 주어질지를 설정하는 값이다.
* input_dim : 단어 vector의 차원을 나타낸다.
* RNN모델은 위와 같이 3차원으로 구성된 tensor를 입력받게 된다.
출력 tensor

* 우리가 앞서 살펴본 3D 형태의 입력 tensor가 memory cell을 거쳐서 어떻게 출력되는지를 살펴보겠다.
* 위 두 개의 그림 중 왼쪽은 마지막 timestep에서만 출력($h_3$)을 내보내는 모델(many to one)이고, 오른쪽 그림은 모든 time step마다 출력 $h_1, h_2, h_3$을 내보내는 모델(many to many)이다.
* 마지막 time step에서만 output을 출력하게 될 경우 output tensor는 2차원 형태인 (batch_size, output_dim)가 출력된다.
* 반면 매 time step에서 output을 출력하면 각 time step의 값들을 모아 한 번에 3차원 tensor 형태로 내보내게 되며 (batch_size, timesteps, output_dim) 형태로 출력하게 된다.
* 매 time step마다 hidden state를 출력하고 싶다면 'return_sequences=True'로 설정해 주면 된다.
keras를 통해 input, output 이해하기
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import SimpleRNN
model=Sequential()
model.add(SimpleRNN(3, input_shape=(2,10)))
model.summary()
# Model: "sequential"
# _________________________________________________________________
# Layer (type) Output Shape Param #
# =================================================================
# simple_rnn (SimpleRNN) (None, 3) 42
# =================================================================
# Total params: 42
# Trainable params: 42
# Non-trainable params: 0
# _________________________________________________________________* 위 모델은 hidden size를 3(hidden state vector의 dimension을 3차원으로 설정), timesteps를 2, input dimension을 10으로 설정한 모델이다. batch size는 설정하지 않았다.
* batch size를 설정하지 않았기 때문에 output shape의 첫 번째 차원 값이 None이고 hidden state의 size를 3으로 설정했기 때문에 두 번째 차원의 값이 3인 것을 확인할 수 있다.
model=Sequential()
model.add(SimpleRNN(3, batch_input_shape=(8,2,10), return_sequences=True))
model.summary()
# Model: "sequential_3"
# _________________________________________________________________
# Layer (type) Output Shape Param #
# =================================================================
# simple_rnn_3 (SimpleRNN) (8, 2, 3) 42
# =================================================================
# Total params: 42
# Trainable params: 42
# Non-trainable params: 0
# _________________________________________________________________* 이 모델은 바로 전에 살펴봤던 모델에 batch_size를 추가하고 return_sequence를 True로 설정한 모델이다.
* output shape를 살펴보면 batch_size에 해당하는 값과, timesteps에 해당하는 값이 추가된 것을 알 수 있다.
파이썬으로 RNN구현하기
* 이번엔 keras를 사용하지 않고 numpy만을 사용해 직접 RNN을 구현해보려고 한다.
import numpy as np
timesteps=10
input_dim=4
hidden_size=8
inputs=np.random.random((timesteps, input_dim))
hidden_state_t=np.zeros((hidden_size,))
Wx=np.random.random((hidden_size, input_dim))
Wh=np.random.random((hidden_size, hidden_size))
b=np.random.random((hidden_size,))
total_hidden_states=[]
for input_t in inputs:
output_t = np.tanh(np.dot(Wx, input_t)) + np.dot(Wh, hidden_state_t) + b
total_hidden_states.append(output_t)
hidden_state_t = output_t
total_hidden_states=np.stack(total_hidden_states, axis=0)
print(total_hidden_states)
# [[2.35062052e+06 2.65607333e+06 2.60000353e+06 3.60981807e+06
# 2.63014104e+06 1.40114611e+06 2.47660324e+06 2.29782556e+06]
# [9.72580184e+06 1.09896265e+07 1.07576344e+07 1.49357894e+07
# 1.08823307e+07 5.79730546e+06 1.02470638e+07 9.50735863e+06]
# [4.02409546e+07 4.54700853e+07 4.45102066e+07 6.17975150e+07
# 4.50261446e+07 2.39866164e+07 4.23977014e+07 3.93371338e+07]
# [1.66498800e+08 1.88134568e+08 1.84163025e+08 2.55690059e+08
# 1.86297743e+08 9.92457261e+07 1.75422442e+08 1.62759199e+08]
# [6.88896438e+08 7.78415418e+08 7.61982979e+08 1.05792937e+09
# 7.70815474e+08 4.10633750e+08 7.25818416e+08 6.73423664e+08]
# [2.85034066e+09 3.22072955e+09 3.15273958e+09 4.37723135e+09
# 3.18928444e+09 1.69901600e+09 3.00310705e+09 2.78632135e+09]
# [1.17934154e+10 1.33259165e+10 1.30446049e+10 1.81109958e+10
# 1.31958109e+10 7.02975677e+09 1.24254934e+10 1.15285326e+10]
# [4.87957982e+10 5.51365917e+10 5.39726519e+10 7.49350772e+10
# 5.45982737e+10 2.90859416e+10 5.14110497e+10 4.76998332e+10]
# [2.01894857e+11 2.28130181e+11 2.23314327e+11 3.10047325e+11
# 2.25902866e+11 1.20344420e+11 2.12715580e+11 1.97360251e+11]
# [8.35349246e+11 9.43899106e+11 9.23973286e+11 1.28283505e+12
# 9.34683486e+11 4.97930565e+11 8.80120485e+11 8.16587107e+11]]* Wh의 size는 (hidden size, input_dim)으로 설정해야 한다. 그래야지 input_dim size의 vector와 곱했을 때 (hidden size, 1) 크기의 벡터, 즉 사전에 설정해 놓은 hidden size 크기와 동일한 vector가 출력되기 때문이다.
* 마찬가지로 Wh는 hidden state를 input으로 받아 hidden state를 출력하기 때문에 (hidden size, hidden size)크기의 가중치 벡터가 되어야 한다.
심층 RNN(Deep Recurrent Neural Network)

* 심층 RNN은 은닉층이 2개 이상 존재하는 RNN을 뜻한다.
* 그림에서 볼 수 있다시피 첫 번째 은닉층은 동일한 time step의 다음 은닉층에게 hidden state를 전달해야 한다. 때문에 코드로 구현할 때는 첫 번째 은닉층에는 무조건 return_sequences=True를 설정해 주어야 한다.
model=Sequential()
model.add(SimpleRNN(hidden_size, input_length=10, input_dim=5, return_sequences=True))
model.add(SimpleRNN(hidden_size, return_sequences=True))
양방향 순환 신경망(Bidirectional Recurrent Neural Network)
* 번역과 같은 작업을 할 때 단어를 순차적으로 앞에서부터 읽는 것 보다 문장 전체를 읽어보고 번역을 하는 것이 더 도움이 되는 경험을 해본 적이 있을 것이다.

* 이와 마찬가지로 Bidirectional RNN도 문장 전체에 대한 정보를 활용하기 위해 두 개의 메모리셀을 사용한다. 한 메모리 셀은 앞에서부터 전달되어 온 hidden state를, 다른 메모리 셀은 뒤에서부터 전달된 hidden state를 현재 시점의 출력에 활용한다.
from tensorflow.keras.layers import Bidirectional
timesteps=10
input_dim=5
model=Sequential()
model.add(Bidirectional(SimpleRNN(hidden_size, return_sequences=True), input_shape=(timesteps, input_dim)))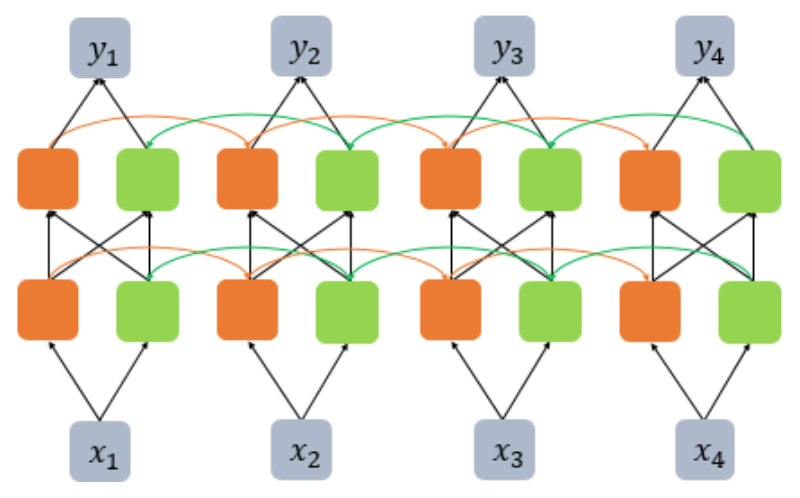
* 양방향 RNN도 역시 deep한 network를 구현하는 것이 가능하다.
model = Sequential()
model.add(Bidirectional(SimpleRNN(hidden_size, return_sequences = True), input_shape=(timesteps, input_dim)))
model.add(Bidirectional(SimpleRNN(hidden_size, return_sequences = True)))
model.add(Bidirectional(SimpleRNN(hidden_size, return_sequences = True)))
model.add(Bidirectional(SimpleRNN(hidden_size, return_sequences = True)))
1) 순환 신경망(Recurrent Neural Network, RNN)
RNN(Recurrent Neural Network)은 시퀀스(Sequence) 모델입니다. 입력과 출력을 시퀀스 단위로 처리하는 모델입니다. 번역기를 생각해보면 입력은 번 ...
wikidocs.net
'Deep Learning > 자연어처리' 카테고리의 다른 글
| RNN을 이용한 텍스트 생성 (0) | 2021.12.17 |
|---|---|
| RNN 언어 모델(RNNLM) (0) | 2021.12.17 |
| 피드포워드 신경망 언어 모델(NNLM) (0) | 2021.12.16 |
| Keras를 통한 SimpleRNN, LSTM 출력값의 이해 (0) | 2021.12.16 |
| LSTM, GRU (0) | 2021.12.16 |



